


So far this little InfraAsCode series was all about declarative Ansible playbooks and Git version control. In this last post we go full circle and discover how CI/CD pipelines helps with automation workflows, taking full advantage of good software development practices.
This post is divided into three parts. We will learn
- How to lint, validate and test input data
- How to implement a GitLab CI/CD pipeline for workflow automation
- How a change management workflow might look like with InfraAsCode
Linting
To achieve a high degree of automation we need to validate the input data, in our case provided by the simple group_vars.yml data model file. The first step is usually linting to rule out syntax and formatting errors, so we need yamllint installed to our Ansible control node.
Yamllint
$ sudo yum install yamllint
A little test run reveals two flaws.

So I actually missed the three dashes at the beginning of the file and added one empty line. That has to be corrected.
---
syslog_server: - 192.168.10.12 - 10.10.10.10 - 1.1.1.1
Ansible-lint
The same procedure can be used to validate whole ansible playbooks against common best practices, by installing the additional library ansible-lint.
$ sudo yum install ansible-lint (...) $ ansible-lint syslog.yml $ ansible-lint syslog_test.yml $
No errors, so the playbooks are fine.
Input Data Verification
Now that we know the group_vars.yml is readable, we need to make sure that the list of syslog servers inside meets some technical and organisational criteria, like:
- Every entry is a valid IPv4 address
- The IP has to be in the range of the companies internal subnets
- We need at least two active syslog servers due to redundancy
There are several programmatic ways to validate the list, from easy to difficult / more powerful:
- Ansible asserts
- Plain Python with ipaddress library
- JSON Schema
- Pytest
For the sake of simplicity, I take Ansible again and use asserts to validate the requirements with three tasks.
---
- name: Verify syslog server in group_vars.yml hosts: localhost gather_facts: false vars_files: - group_vars.yml tasks: - name: ASSERT THAT EVERY ENTRY IS A VALID IPv4 ADDRESS assert: that: - item | ipv4 == item fail_msg: "{{ item }} is not a valid IPv4 address <FAILURE>" success_msg: "{{ item }}: <OK>" quiet: true loop: "{{ syslog_server }}" - name: ASSERT THAT EVERY ENTRY BELONGS TO A VALID SUBNET assert: that: - "'192.168.0.0/16' | network_in_network(item) or '10.0.0.0/8' | network_in_network(item)" fail_msg: "{{ item }} does not belong to a valid subnet <FAILURE>" success_msg: "{{ item }}: <OK>" quiet: true loop: "{{ syslog_server }}" - name: ASSERT THAT AT LEAST TWO SYSLOG SERVER ARE PRESENT assert: that: - syslog_server | length >= 2 fail_msg: "At least two syslog server are mandatory <FAILURE>" success_msg: "{{ syslog_server | length }} syslog server in the list: <OK>" quiet: true
A playbook run reveals actually another mistake.
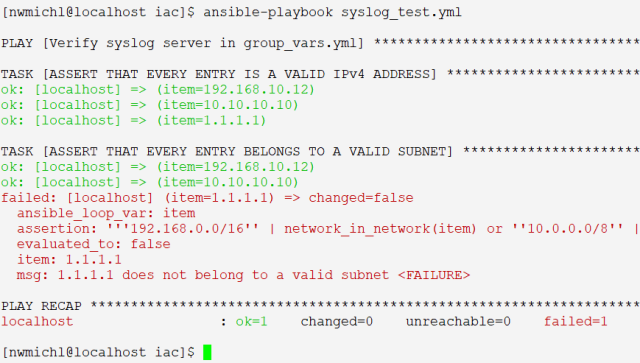
John from operations mistyped the third syslog server, it needs to be corrected to 10.1.1.1, to become part of the internal network.

Test Deployment
As it is best practice to test changes against a production near environment, we push the new configuration to a test system and examine the result.
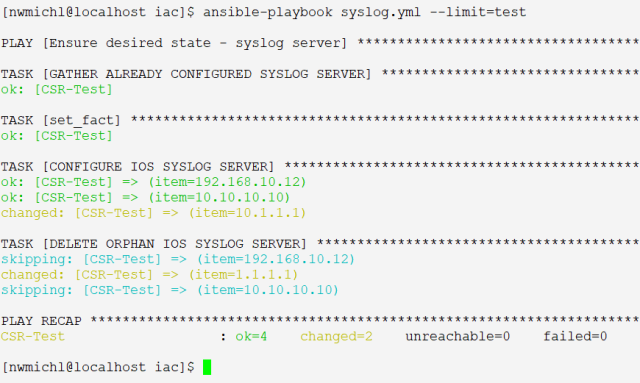
No issue, everything looks great. It is common, by the way, to spin up virtual network equipment in a VM or container form-factor only for this exact test case.
So, with all these guard rails in place, we are confident to deploy the changes to production. Of course, there is no limit regarding further tests like syslog server reachability or send/receive a syslog message from the test switch and so on. This is exactly the point where the Network Engineers expertise in the form of procedure documentation brings added value to the automation table. But, as always, there has to be a balance between effort and benefit 
GitLab CI/CD Pipeline
First of all: What’s the fuss about pipelines and CI/CD, you might ask, and why do we need it? Well, it’s the matter of automation all over again. All these steps above with linting, input validation and (test) deployment can be better done by a machine in a defined, repeatable manner. Think of CI/CD pipelines as a workflow definition tool triggered by changes to a GitLab repository.
Software developers make extensive use of this method to ensure code quality combined with shorter deployment cycles – that’s the meaning of CI (continuous integration) and CD (continuous deployment).
Prerequisites
To make the pipeline magic happen, we need a way for the GitLab repository to communicate with and take action at our Ansible control node. This can be achieved with an extra piece of software, the gitlab-runner. But first we need to obtain some information, the GitLab URL and a registration token (Gitlab, Settings, CI/CD, expand Runners).
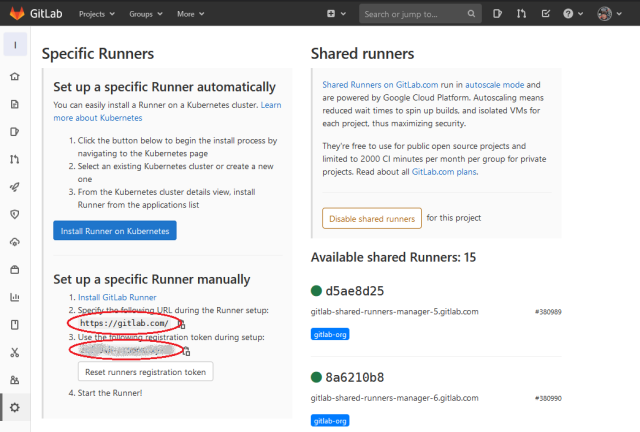
Installation and configuration of the gitlab-runner:
$ sudo yum install gitlab-runner $ sudo gitlab-runner register Enter the GitLab instance URL (for example, https://gitlab.com/): https://gitlab.com Enter the registration token: Th1s1s@T0k3n Enter a description for the runner: ansible_control_node Enter tags for the runner (comma-separated): verify, test, deploy Enter an executor: shell
Tags are a way to reference different gitlab-runner for different purposes. Maybe you have a dedicated test environment? In our case, all three tags (verify, test, deploy) end up on the same Ansible host.
If the registration was successful, the runner regularly polls the GitLab repository for new tasks. Use $ sudo gitlab-runner verify or the GitLab GUI to verify the operation.

The Pipeline
That’s the easy part! Just create a new file in the main repository called .gitlab-ci.yml and describe the desired stages of the pipeline like this (yeah, I know, it’s YAML again):
---
stages: - lint - validate - test - deploy variables: GIT_STRATEGY: clone yamllint: stage: lint tags: - verify script: - yamllint group_vars.yml ansiblelint_syslog_test: stage: lint tags: - verify script: - ansible-lint syslog_test.yml ansiblelint_syslog: stage: lint tags: - verify script: - ansible-lint syslog.yml validate_input: stage: validate tags: - verify script: # Execute syslog_test playbook with group_vars.yml - ansible-playbook syslog_test.yml test_deployment: stage: test tags: - test script: # Execute production playbook on a test switch - ansible-playbook syslog.yml --limit=test deploy: stage: deploy only: refs: - master tags: - deploy script: # Execute production playbook only on master branch - ansible-playbook syslog.yml --limit=ios,nxos
It needs a list of stages (lint, validate, test, deploy) followed by jobs that describe the desired actions per stage. All these shell commands get executed as the gitlab-runner user at the ansible_control_node after cloning the current repository to a directory in the /home/gitlab-runner/builds/<TOKENPREFIX>/0/NWMichl/iac path.
In production environments you would better use Python virtualenv or prebuild container images as execution environment for proper segmentation of pipeline runs by different projects / users.
So, once this new file is committed to the master branch, the pipeline starts and hopefully successfull completes. At this point, the master branch permanently represents the configured state of the network regarding the syslog configuration, if
- The pipeline completes successfully,
Pipeline passed - Nobody changes device config the old CLI way …

Important: The deploy job only runs when the pipeline gets triggered by changes to the master branch of the repository, we’ll learn why right away.
Another cool thing: We now have the output of all remote tasks in one place to quickly spot where and why something went wrong.

Change Workflow
Now, how do we use all this in the real world to ease operations and lower friction and failures? I would like to walk you through a usual change process, initiated by IT Operations.

We take advantage of the GitLab permissions and decided that only Network Engineers are allowed to make changes to the master branch aka the production environment as project maintainer. Operations can propose changes in new branches, but not push to production, because they get the developer role.
IT-Operations proposes a change
John from operations remembers that he forgot to delete the decommissioned syslog-server 10.10.10.10, but now he just has to log into the GitLab project and edit the group_vars.yml while creating a new branch johnops-master-patch-98769. Yes, he could also clone the project to his workstation and push changes back to the repository, but with only one line to change, the GUI is way faster.

Edit opens a simple web-based text editor.

After Commit changes, John can create a new merge request to eventually apply the changes to the production / master branch.

In the mean time, the pipeline runs for the new branch johnops-master-patch-98769 and validates the changes against the conditions specified by the network team, without deployment to production – the last stage deploy is skipped, because this is not the master branch.

Network Team Approval
The Network team gets a notification via mail / slack or notices a new merge request popping up in the GitLab GUI.
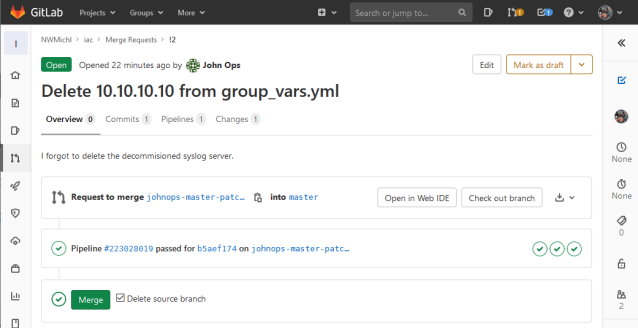
We immediately see the successful pipeline run and can examine the proposed changes more closely via Open in Web IDE, for instance.

Ok, so only the group_vars.yml changed, one syslog server was deleted, we can push this to production, by choosing Merge.
Now that something changed in the master branch the pipeline runs again including the deploy stage and after a minute we see it succeed in the main repository view.

What did we just accomplish? A well tested, network wide configuration change without anyone touching a single device, including documentation and versioning of every step. Just hit History or Blame to understand the true power of Git.

Closing
Congratulations, and welcome to NetDevOps land!
“NetDevOps brings the culture, technical methods, strategies, and best practices of DevOps to Networking.”
This blog post series covered the main methods and tools to enable small, frequent network deployments/changes, that get automagically validated, tested and executed. I really hope that I managed to transport the immense value of this practice, because above all, NetDevOps is a mindset/culture and needs people aboard.
Change is good!





