


Infrastructure as code is all the rage, but sounds hypercomplex. How should it be possible to represent a router or even a whole network as code? We definitely need deep software development skills and an extensive version control plus CI/CD pipeline, right? Well, no! Actually, it’s pretty darn simple and by the end of this blog post you might wonder what took you so long to get started.
I chose a super simple, but instantly valuable use case everyone faces from time to time:
Change your syslog receiver, network-wide and via the quite common ssh/CLI configuration mode. A NETCONF/RESTCONF or API based configuration would make it even easier!
Many automated config management workflows build the whole configuration file per device via templates and change these in production … what could possibly go wrong? Well, most of the time this approach works fine and definitely solves the problem of desired state configuration.
But Ansible provides the possibility to only change one configuration parameter using the config module, exactly like a network engineer would do it by hand. That’s a very safe way to expand the automation footprint over time, without imposing too much risk to our beloved brownfield environments.
Why bother?
When we think hard about data models and manage to represent whole networks (and services) as code in text files, we are able to utilize git repositories and benefit from the very best the software development discipline has to offer.
- Configuration and documentation in one place
Those text files describing the desired state of a network ARE the documentation at the same time.
Or, as these files are machine readable, it’s easy to autogenerate pretty documentation pages, via markdown for instance. - Versioning
The ultimate answer to the “Who changed what, when, where, why?” is build in. - Single source of truth
- Workflows via deployment pipelines
Enforce peer review before putting a change into production? Easy. - Automated tests and validation
For instance: Catch mistyped IPs by a machine, not a human or the network device. - Powerful team collaboration via GitHub / GitLab (even cross-silo)
You might have heard about ‘issues’, these little async messaging nuggets with rich context about your repository? Think Jira, Remedy, ServiceNow tickets, but on steroids.
All this enables simple deployment of full IT-Services from networking up to the app layer with way more speed, reliability and security, while reducing risk and friction in day2 operations. Plus, it helps to pay back technical debt and ultimately opens the door to a DevOps mindset for the whole IT organisation.
That’s the big picture, but fortunately, we can start small and iterate over our automation stack, step by step.
Requirements.txt
Just a basic Ansible installation on a Linux based control node and one additional library are needed to work through this piece.
$ sudo pip install netaddr
Basic playbook
Let’s start with a simple playbook to get the job done for Cisco IOS devices. We want to make sure, that two syslog receiver 192.168.1.12 and 10.10.10.10 are configured at each host. Without automation, a network engineer would ssh into the router and type
CSR-1#conf t Enter configuration commands, one per line. End with CNTL/Z. CSR-1(config)#logging host 192.168.10.12 CSR-1(config)#logging host 10.10.10.10 CSR-1(config)#exit CSR-1#copy run start Destination filename [startup-config]? Building configuration… [OK] CSR-1#exit
Well, the Ansible playbook needs one task using the ios_config module to do exactly the same. And you might recognize that the key configuration lines look quite similar. That’s one of the reasons why Ansible is so easy to onboard as an automation platform.
---
- name: Ensure syslog servers are configured hosts: all gather_facts: false connection: network_cli tasks: - name: CONFIGURE IOS SYSLOG SERVER ios_config: lines: - logging host 192.168.10.12 - logging host 10.10.10.10 save_when: changed when: ansible_network_os == 'ios'
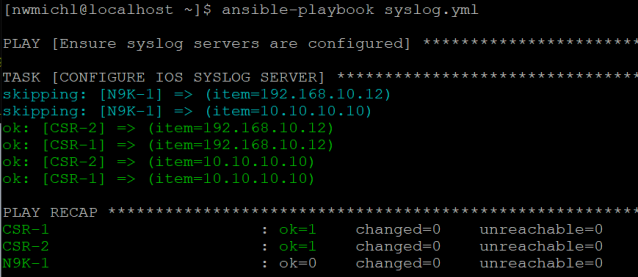
Invoked at your Ansible control node, it looks like this.

Ok, so now it’s easy to scale and configure even large networks when the playbook gets executed without the --limit option. This lab has three switches.
- CRS-1 is unchanged
The syslog servers are already there – the beauty of built-in idempotency. - CRS-2 gets configured
- N9K-1 is skipped
Because of the task conditional, it has the wrong network_os.

Adding variables and loops
Next we try to get a little more flexible. The number of syslog server might vary, we don’t want to touch the ios_config task every time when something changes and most importantly, we might want to use the same syslog servers in other configuration tasks, like NX-OS for example.
Variables and loops come to the rescue. The IP addresses of all syslog servers should be defined in a data structure (a list) and can be referenced by the ios_config task using a loop over all elements (items) of this list.
---
- name: Ensure syslog servers are configured hosts: all gather_facts: false connection: network_cli vars: syslog_server: - 192.168.10.12 - 10.10.10.10 tasks: - name: CONFIGURE IOS SYSLOG SERVER ios_config: lines: - logging host {{ item }} save_when: changed loop: "{{ syslog_server }}" when: ansible_network_os == 'ios'
Due to the loop, we now get detailed information about what syslog server has been configured where, during the playbook run.
Data Model – Outsourcing of Variables
This playbook currently fulfills two purposes. It defines WHAT should be the state of your network (two syslog servers via IP) and HOW it should be done (the ios_config task with the relevant Cisco IOS commands). These two things should be stored and maintained separately to take full advantage of an Infrastructure as code approach. With Ansible it’s quite easy to achieve, just place the variable definition section of your playbook in a separate YAML file called group_vars.yml:
syslog_server: - 192.168.10.12 - 10.10.10.10
That’s the beginning of your data model. You might add things like NTP and AAA server, vlan definitions, VRF, SNMPv3 user and so on. Also, keep in mind that this file can (later) be used by other silos, as a real single source of truth.
We include this variable file in the Ansible playbook statically by using the vars_files: definition in the playbook header. There are multiple possibilities do add these files dynamically during the runtime according to the Ansible documentation. Furthermore, Ansible allows a hierarchical order of this data model files and thus defines variable precedence rules.
---
- name: Ensure syslog servers are configured hosts: all gather_facts: false connection: network_cli vars_files: - group_vars.yml tasks: - name: CONFIGURE IOS SYSLOG SERVER ios_config: lines: - logging host {{ item }} save_when: changed loop: "{{ syslog_server }}" when: ansible_network_os == 'ios'
It’s a valid approach to run this playbook frequently via a cron job. Then group_vars.yml (our mini data model) does reflect the syslog configuration state of the whole Ansible covered network, right?
Well, almost.
The playbook actually works only one way, it can assure that the syslog servers according to group_vars.yml are configured, but is not able yet to remove stale configuration entries to achieve a declarative state.
Desired State Configuration
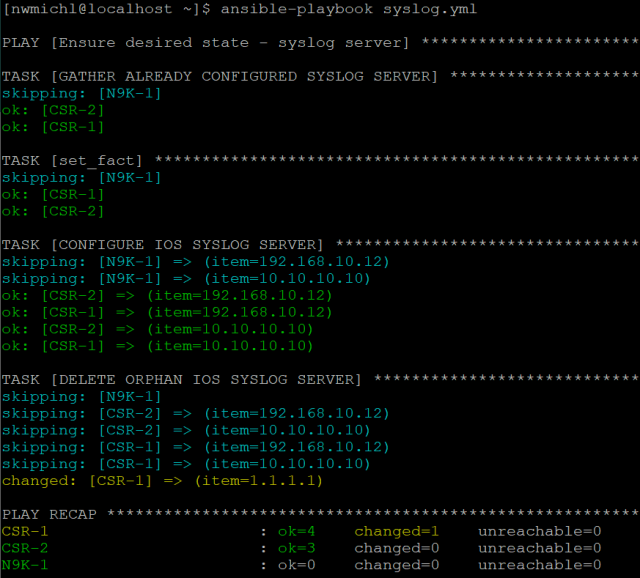
The playbook needs three more tasks and has now the following structure.
- Gather already configured syslog server via IOS command
- Parse the IOS command output and store the result as a new list
- Configure syslog server according to the group_vars.yml file
- Delete orphan syslog server entries
---
- name: Ensure desired state - syslog server hosts: all gather_facts: false connection: network_cli vars_files: - group_vars.yml tasks: - name: GATHER ALREADY CONFIGURED SYSLOG SERVER ios_command: commands: show run | incl logging host register: syslogserver when: ansible_network_os == 'ios' - set_fact: configured_syslogserver: "{{ syslogserver.stdout[0].split() | ipaddr('address') }}" when: ansible_network_os == 'ios' - name: CONFIGURE IOS SYSLOG SERVER ios_config: lines: - logging host {{ item }} save_when: changed loop: "{{ syslog_server }}" when: ansible_network_os == 'ios' - name: DELETE ORPHAN IOS SYSLOG SERVER ios_config: lines: - no logging host {{ item }} save_when: changed loop: "{{ configured_syslogserver }}" when: ansible_network_os == 'ios' and item not in syslog_server
The real magic happens in the set_fact task, where the variable syslogserver of the previous task gets parsed to build a list of configured_syslogservers.
| Variable | Result |
|---|---|
| {{ syslogserver }} type dictionary |
{ “ansible_facts”: { “discovered_interpreter_python”: “/usr/bin/python” }, “changed”: false, “failed”: false, “stdout”: [ “logging host 192.168.10.12\nlogging host 10.10.10.10“ ], “stdout_lines”: [ [ “logging host 192.168.10.12”, “logging host 10.10.10.10” ] ] } |
| {{ syslogserver.stdout }} type list |
[ “logging host 192.168.10.12\nlogging host 10.10.10.10“ ] |
| {{ syslogserver.stdout[0] }} type string |
“logging host 192.168.10.12\nlogging host 10.10.10.10“ |
| {{ syslogserver.stdout[0].split() }} type list |
[ “logging”, “host”, “192.168.10.12“, “logging”, “host”, “10.10.10.10“ ] |
| {{ syslogserver.stdout[0].split() | ipaddr(‘address’) }} type list |
[ “192.168.10.12“, “10.10.10.10“ ] |
The last task just loops over all of these configured_syslogservers and deletes the ones not included in the desired list of the group_vars.yml.
That’s it. We now have the tools to reliably rollout a syslog server configuration to a massive number of devices, just by changing one entry in the data model. You might be surprised what this little guy finds in your network using the --check or --diff mode.
Grow Step by Step
It’s true, this playbook only covers syslog configuration with Cisco IOS devices, but it’s relatively easy to expand to other platforms using ansible_network_os =='', or to add new configuration tasks. The necessary steps are always the same as above.
I’d like to finish with some production-level data models to show where things might be heading.


Closing
Quick recap. We covered the first necessary part of an Infrastructure as code based config management.
- Figure out how the manual configuration would look like
- Develop a declarative playbook
- Generate a data model

The data model is the essential part and should in particular follow the DRY (Don’t repeat yourself) principle. It needs an experienced network engineer to decide where to store a parameter (global, group, site, host_vars), based on the network design.
All this works nicely as long as you are the only person messing with automation files and can live with funny names like group_vars_v4_revisitedQ3_2019_final.yml. Everyone else should definitely read the next part about version control and Git to take a more mature and team friendly approach.





